Wuispa:一个用户友好的网络爬虫工具
Wuispa是由mxmandela开发的基于GUI的网络爬虫。它旨在允许用户从任何网站收集数据,而无需任何编码知识。通过点选界面,Wuispa使任何人都可以轻松选择网页上的特定内容块并提取所需信息。
该爬虫通过允许用户选择要抓取的页面和内容块来工作。然后,它循环遍历每个项目并创建提取数据的列表。此列表可以导出为CSV或JSON,也可以通过REST API使用。
Wuispa作为辅助选择内容块所需项目的扩展。它读取元素路径,以便爬虫可以提取类似的项目。实际的爬取工作由一个启动无头Chrome浏览器的Python程序完成。目前,Wuispa在Heroku平台上运行。
Wuispa的一个优点是其用户友好性。与其他可能具有陡峭学习曲线或需要信用卡信息的爬虫不同,Wuispa只需要用户的电子邮件地址进行身份验证。这使用户可以立即尝试而无需等待时间或其他要求。
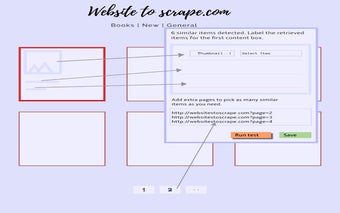
Wuispa的界面简单直观,适用于各个专业水平的用户。所需内容块中的元素会自动检索,用户只需标记所需的元素。这减少了标记数据时的错误,尤其是对于如价格和标题等在其他爬虫中可能难以精确选择的电子商务产品字段。
此外,Wuispa允许用户跟随内容块中的链接,从详细页面提取信息。这意味着用户不仅可以收集主要数据,还可以从链接页面中获取其他详细信息。例如,可以轻松从详细页面提取产品描述,而无需进行大量配置。这确保用户可以提取所需的所有相关信息。
Wuispa采用人类浏览的方式进行数据收集,确保被爬取的网站不会遭受DOS攻击。爬取过程受限,因此如果从一个站点爬取多个页面,则会按顺序进行,而不是一次性全部进行。这使用户可以在后台等待数据被提取,而不会对目标网站造成过大压力。
在未来的版本中,Wuispa计划包括数据转换功能。这意味着用户将能够使用固定值或百分比来翻译收集到的数据和修改数字,以及其他可能性。这个附加功能将为用户在处理提取的数据时提供更大的灵活性。
总的来说,Wuispa是一个用户友好的网络爬虫工具,简化了从网站收集数据的过程。凭借其直观的界面、自动化元素检索和跟随链接的能力,Wuispa为各个专业水平的用户提供了方便的解决方案。